Abstract
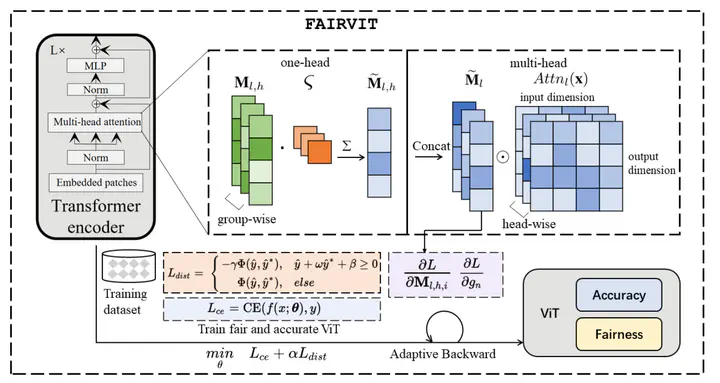
Vision Transformer (ViT) has achieved excellent performance and demonstrated its promising potential on various computer vision tasks. The wide deployment of ViT in real-world tasks requires a through understanding of the societal impact of the model. However, most ViTs do not take fairness into account and existing fairness-aware algorithms designed for CNNs do not perform well on ViT. It is necessary to develop a new fair ViT framework. Moreover, previous works typically sacrifice accuracy for fairness. Therefore, we aim to develop an algorithm that improves fairness without sacrificing accuracy too much. To this end, we introduce a novel distance loss, and deploy adaptive fairness-aware masks on attention layers to improve fairness, which are updated with model parameters. Experimental results show the proposed methods achieve higher accuracy than alternatives, 6.72% higher than the best alternative while reaching a similar fairness result.